

Vector Similarity Search is Hopeless
Uri Merhav
2024-12-03
About 2 years ago, as a machine learning consultant, I had a bunch of occasions to work on projects where we tried to get GPT to be helpful and knowledgeable. In one case, I was trying to make it perform a Customer Support role, another was as a Sales Engineer, and a third was implementing a diagnosis assistant for medical intake interviews.
In all cases, asking GPT to answer questions using its general knowledge was initially impressive but ultimately limited. The model’s general knowledge is outdated, partial, and it finds it incredibly hard to distinguish fact from imagination. In customer support, it will happily make up a feature for your product or fail to know how it works in detail, etc. Ask it about the intricacies of a product that’s constantly evolving, and you have no chance of getting it right just by hoping that the model’s general knowledge will cover the subject.
The solution, of course, is RAG: Retrieval Augmented Generation. This is a fancy term for something super simple. RAG is just “Look at the question, copy & paste some relevant knowledge article plus the question, and tell the model to provide the answer based on those pasted articles.”
Let’s take a concrete example. Let’s say I’m building an automated real estate support agent. I have the rental contracts of all my tenants, and they send in emails with questions and complaints.
Obviously, if you just ask ChatGPT, it has no clue how to answer these questions — there’s nowhere in the model weights that says what’s in my rental lease or the city ordinances that apply to that lease.
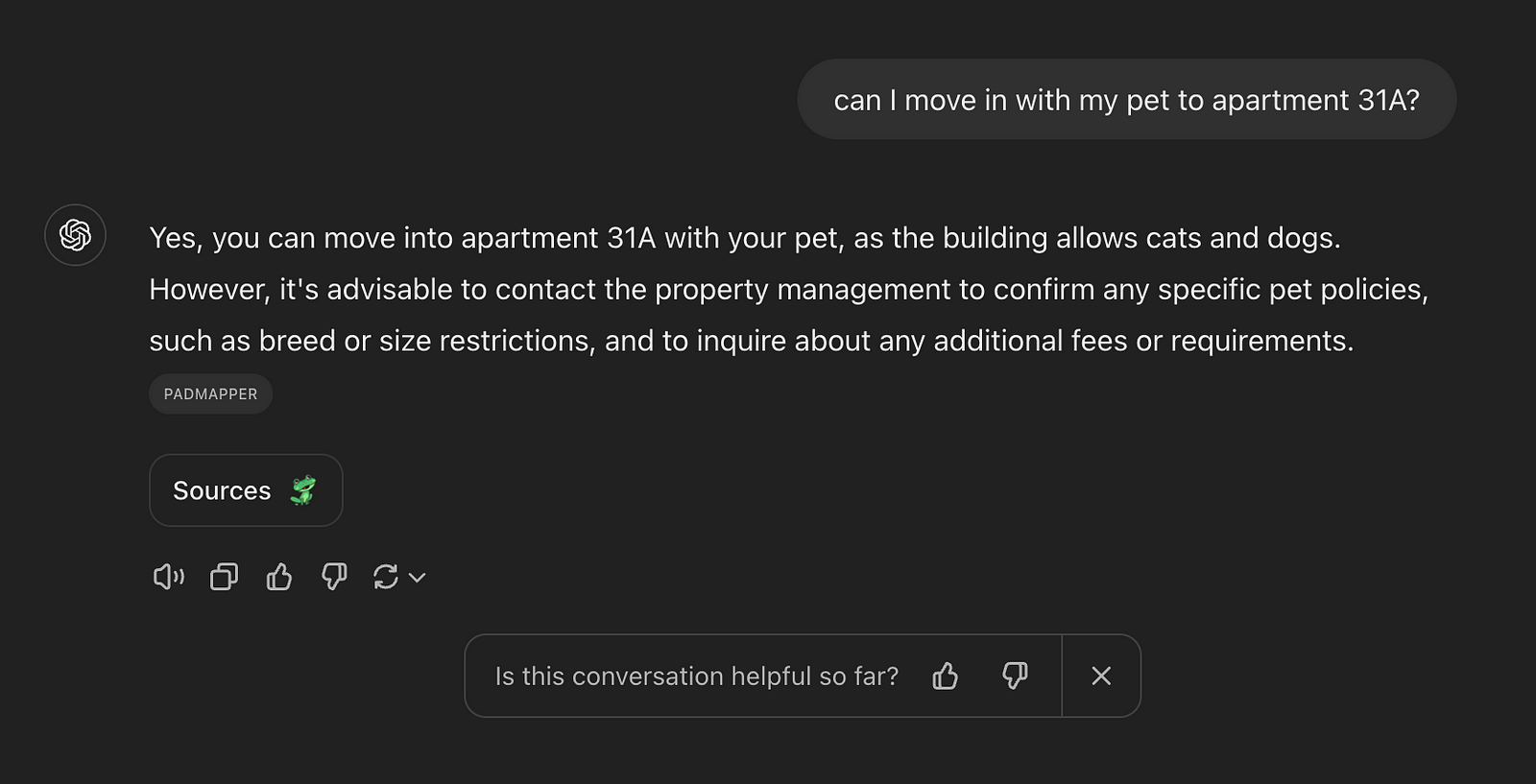 Huh? We'll dig into exactly how it got to this bizarre, confidently incorrect question, later
Huh? We'll dig into exactly how it got to this bizarre, confidently incorrect question, laterOk, so GPT went a bit haywire and, instead of saying “I don’t know,” it chose to search for an answer, found a completely irrelevant source, and made stuff up. If we avoid internet search, you get the typical 4-paragraph-long “I don’t know” that LLMs love to generate.
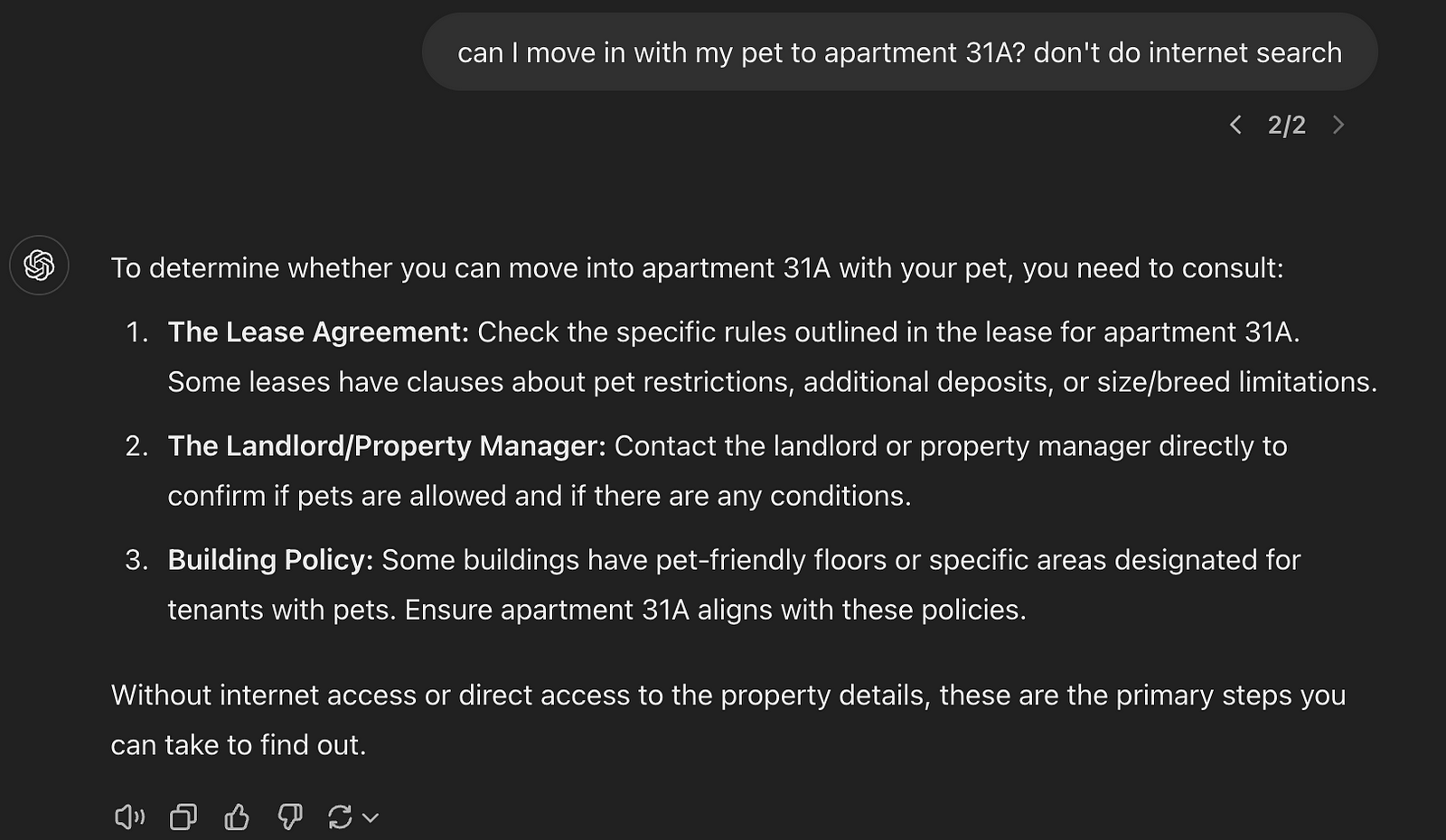
So what happens if I ask the same question while pasting the plain text of the rental lease pets section? I first pasted the relevant page from my rental contract and then asked my question. Magic ensues.
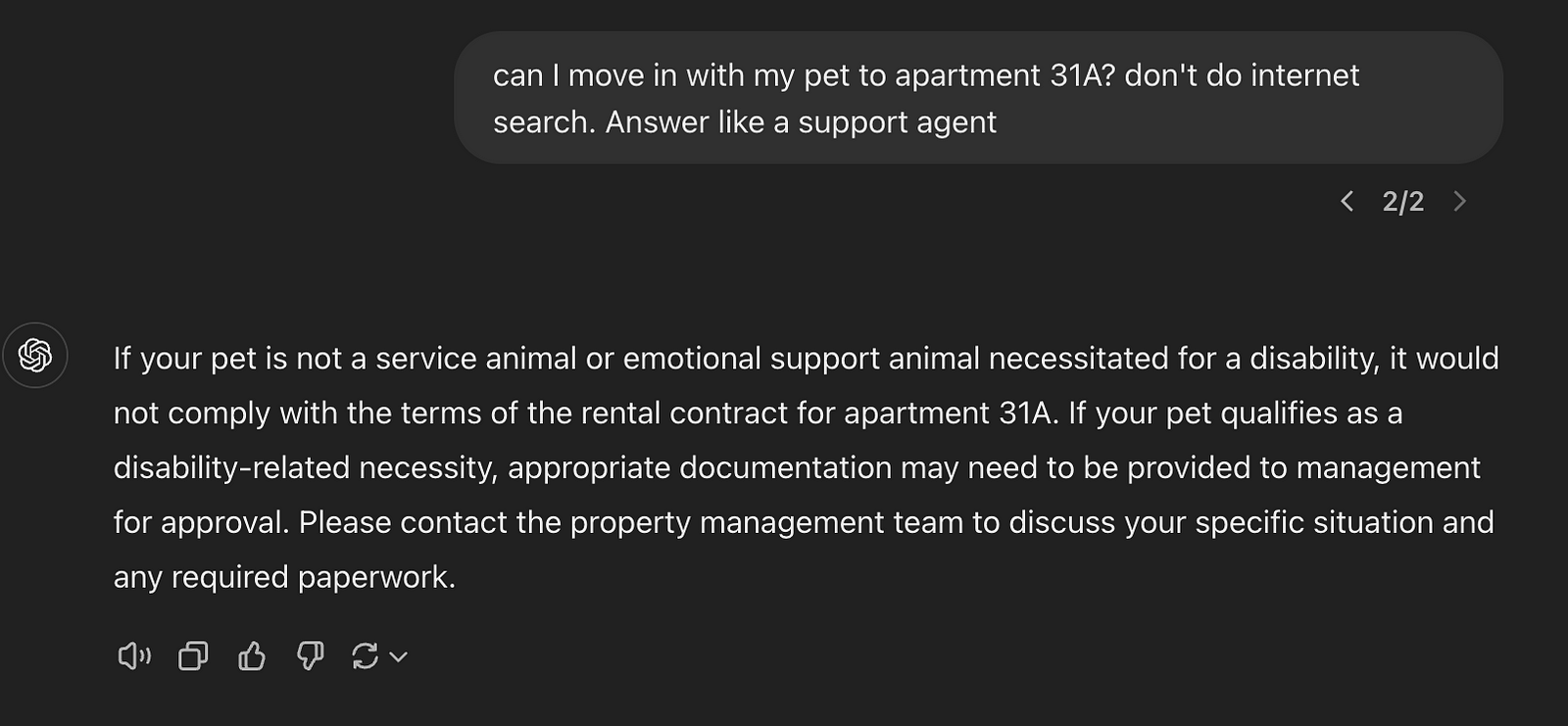
This is a perfect answer. You will get similarly great answers if you fetch the relevant city ordinance, building permit language, etc.
So RAG is awesome. If we find a piece of text that concretely helps in answering the question, LLMs like ChatGPT can extrapolate and adapt the knowledge source to give an authoritative answer. Notice that this supports many other use cases beyond a real estate support bot:
You can help technicians find the relevant steps to troubleshoot problems in complex machines, if only you know how to fetch the relevant manual.
You can help insurance adjudicators decide whether to reimburse an expense, based on the relevant part of an insurance policy document and the medical invoice in question.
You can pull down the latest research papers on the topic that you’re trying to work on to inform your question answering or experiment planning.
Now the niggling question remains — how do we pull down the relevant text snippets that answer the subject at hand? Remember, we have limited context length — we can’t just paste all the documents in the world as context. So how do we choose what supporting text to put in there?
Vector Embedding to the Rescue (?)
The idea of vector embedding is very appealing. Here’s how it works: under the hood, Large Language Models (LLMs) generate an abstract representation of every piece of text you give them. You can take a word, a sentence, or a 50-page document, and transform each of them into a single vector. Text goes in, and a list of numbers comes out.
To take a concrete example, you can plug this entire blog post into OpenAI’s Ada Embedding and get a list of 1,536 numbers that, in some sense, represent this blog post. You could then compare it to other Medium blog posts, and they’ll probably cover similar subjects.
If you want to get technical about how to measure distance between these vectors, we typically just calculate a distance between the vectors — it’s as simple as, for example, taking those two lists of numbers, subtracting them, and summing their squares.
With vector embeddings, search becomes magically easy. Index all your help articles, your API documentation, and any other piece of information you have about your website, and convert each document into a vector. When a new question comes in, embed the entire question or conversation into the same space, and find the closest documents. Now copy and paste these documents as context to your LLM, preceding the user’s input (“Here are some supporting documents, you may use them to answer the question”), and you’re done.
If you want to get more precise localization of relevant text snippets, you can choose to embed documents but also embed separately their comprising sections, paragraphs, etc. This way, you can find a document that’s broadly relevant and drill down to specific paragraphs or sections that seem to be relevant. Sounds magical, right?
This solution is, in fact, pretty magical. You’re leaping all at once from zero search capability to remarkably nuanced search. Let’s first marvel at the magic before we pick it apart:
I can embed the following question: “Hi, I live in apartment 31A, can I bring a pet alligator?” Embedding each paragraph in my 52-page contract, you immediately get as the top section this part:

You can ask about your deposit, and sure enough, one of the top results answers about its amount.
Cracks start to form when we ask more nuanced questions. If I ask, “At what point can you use up my security deposit? What’s the process that lets you spend my deposit money?” the top results don’t actually spell it out.

But if we dig into the second and third results, we do eventually find the relevant text span, which I’ll spare you because it’s long and boring.
So why did the model miss? Simply put, the way it embeds information doesn’t anticipate the exact context for answering.
Vector search measures similarity between spans of text, but doesn’t know what kind of similarity is crucial and which is incidental
Here’s an extreme example. Let’s say I have multiple rental documents for the same tenant, and some of them have expired. A similarity search can easily surface the right paragraph — from the wrong contract.
You can try hacks like prefixing the question text with “The question is being asked on December 2nd, 2024.” But this will not surface the more up-to-date document because, unluckily, the expired rental lease mentions that it expires on December 1st, 2024, which in vector space is very close to December 2nd, 2024. In the real estate legal world, the distance should be infinity — the contract is simply expired. But in vector space, the date looks close, so it seems like a relevant document.
Retrieving an irrelevant document and using it as context is how you get crazy lies in an otherwise great RAG system. Remember how our first example showed ChatGPT giving me a confidently incorrect answer about my apartment because it ran an internet search and fetched some irrelevant source? This is, in fact, a very common failure mode for RAG. You get the right amount from the wrong contract, the right instructions from the wrong manual, etc.
A Good Retrieval is an Indexed Retrieval
In real-life documents, there’s often crisply defined business logic on how to retrieve that document. You can extract the move-in and move-out dates specified in a rental lease. Even better, rather than only indexing these sorts of items to fetch a relevant document, you can index the documents to pre-answer most of the common questions, like a rental amount, deposit amount, or a summary of the pet policy in free-form text, etc.
Let’s walk through a concrete example. I can copy and paste my entire rental lease (all 53 pages of it) and prompt GPT to extract the fields I’m interested in.

If we convert this information into JSON format and extract the same fields consistently, we get a bunch of things for free:
We get consistent, predictable retrieval. We can index all of our documents with the same fields (move-in date, etc.) and run an SQL or MongoDB query to fetch the relevant document.
Better, we can let our AI know how we’ve indexed the document and have it automatically write relevant queries to fetch the relevant document.
Sometimes we don’t need to fetch the entire document, as our index already contains the answer because we predicted it in our index. For example, rental lease questions often hit on the same few aspects of document understanding — the rent amount, payment schedule, move-in date, pet policy, etc. This makes our call to the LLM both way cheaper and way faster. Instead of reading through entire sections of the document, we simply quote from our indexed result.
I believe that this paradigm is very strong. I believe it with enough conviction to found an entire company built, called DocuPanda.io, right around this paradigm.
We make it easy to define a set of fields and extract them with consistent data types and defintion, at scale, across millions of documents. It works even when the doucments contain tables, handwriting, checkmarks, etc.
Here’s what an output looks like in DocuPanda land (I’ve hiddent some fields to save space).

Once you standardize many documents, you can ask free form questions, and rely on the AI to automatically generate the relevant query
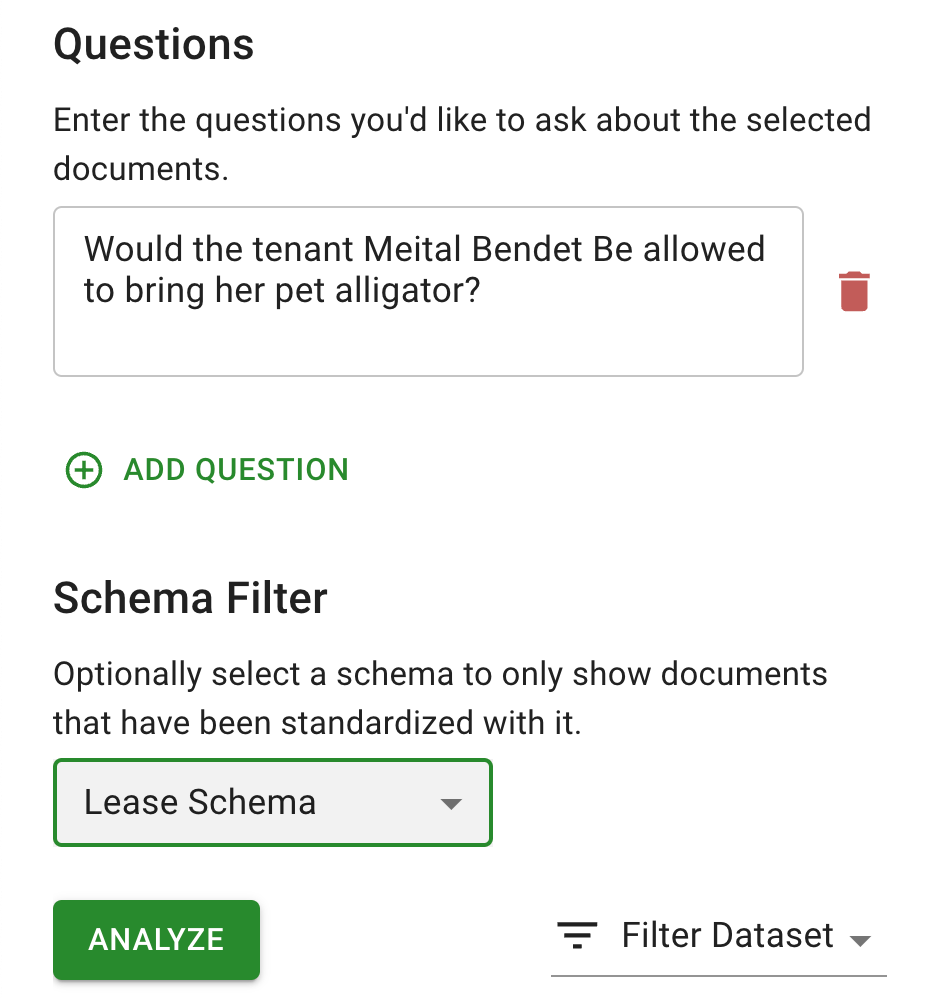
This question triggers a chain where the AI introspects about what fields we have in our schema, (e.g. renter names, pets allowed which is a true/false boolean, Pets Allowed Details which is a short text span). The AI then writes a DB query to fetch the relevant result, read through the records that are returned (e.g. renter name == “Meital Bendet”), and the finally reason about the result, potentially referring to the raw document text as needed.
This gives a final result.
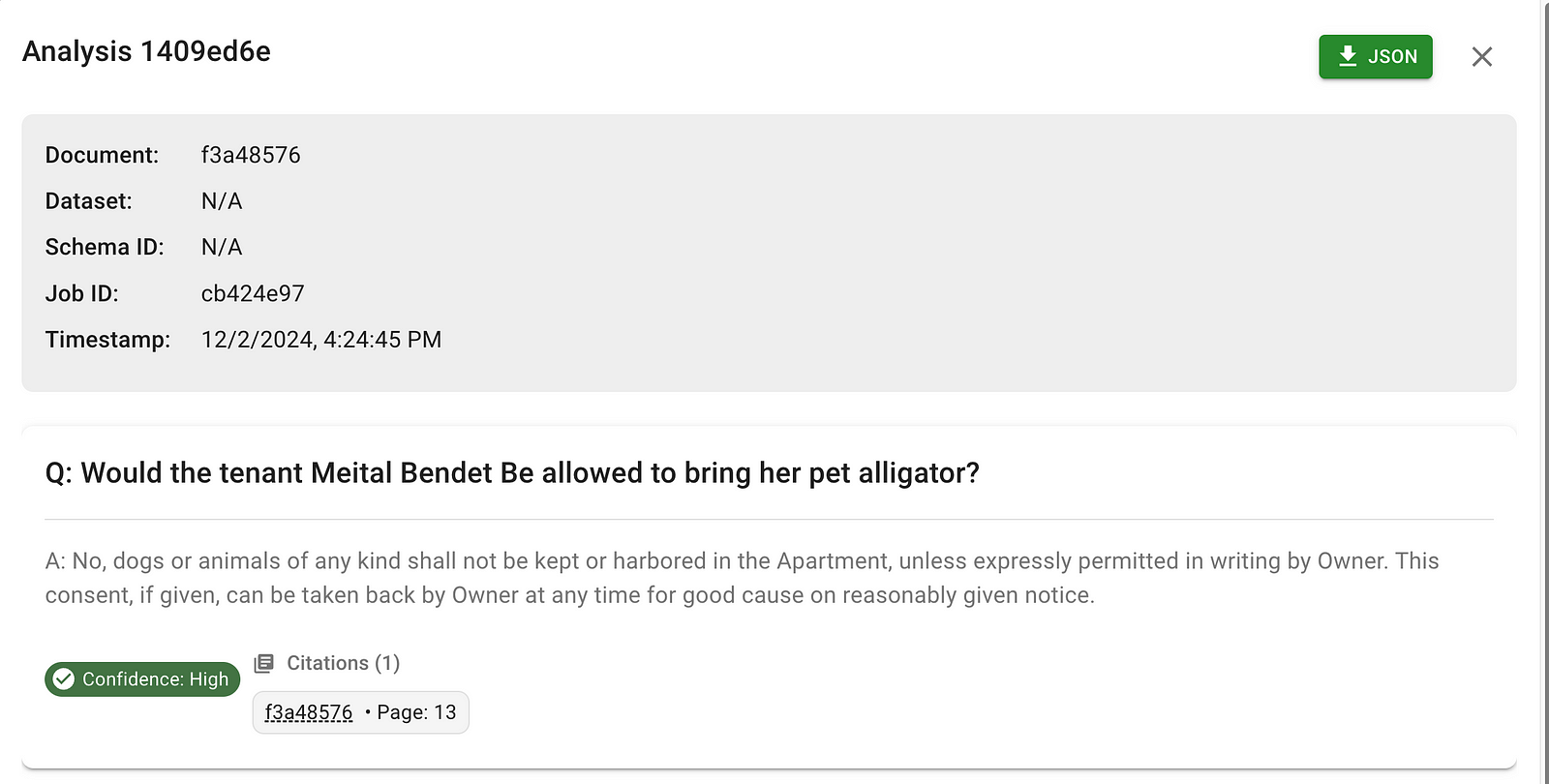
I hope you’ll consider the takeaway that you can build stronger pipelines by spending a bit of time thinking about how your business needs to understand its documents, and indexing your documents once and for all in a way that makes sense for how you intend the documents to be searched for. Also consider trying out DocuPanda. Its the culmination of years of trail and error in this space, and might help you execute faster.
Happy Indexing!
 We’ve been indexing for a couple millennia. Don’t stop now
We’ve been indexing for a couple millennia. Don’t stop now